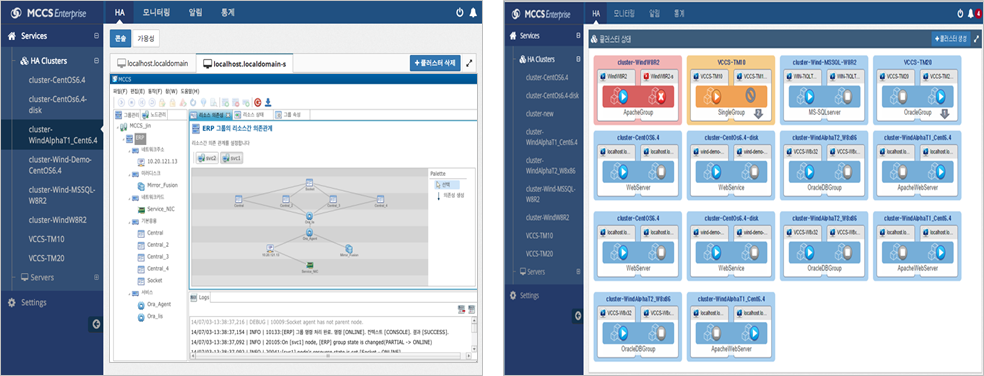
서비스소개
고가용성

고가용성(High-Availability)이란?
중앙 집중화된 관리 콘솔을 통해 전체 인프라에 대한 클러스터 통합 관리 기능을 제공하며, 실시간 장애 감시를 통해 장애 발생 시 최소한의 시간으로 자동 복구를 지원합니다.
-

-
- 장애 감지 ( H/W, Application, disk, network )
- 데이터 실시간 복제 또는 외장스토리지 환경 지원
- WEB GUI ( 한글, 영문 ) 지원
- 구성 환경 : P2P, P2V, V2V
- 지원OS : windows, Linux
-
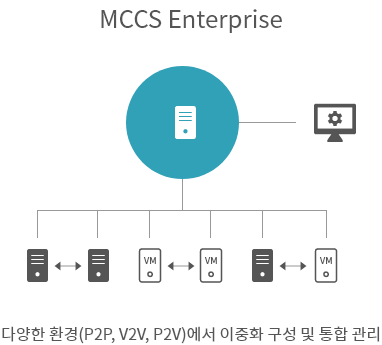
-
- 장애 감지 ( H/W, Application, disk, network )
- 데이터 실시간 복제 또는 외장스토리지 환경 지원
- 구성환경 : P2P, P2V, V2V, Single Node
- WEB GUI 통합관리 모니터링 제공(한글, 영문)
- 사전 징후 및 후속조치
- 시스템 자원 모니터링 ( CPU, MEM, DISK
- 시스템, Applications No Response 후속조치 - System Hung 감지 후 자동 조치 기능
- 알람서비스 : SMS, e-mail, Hangout
- 장애 통계 분석 및 보고서
기대 효과

가용성 증대
IT 서비스 연속성 증대로
장애로 인한 비용 손실을
최소화하며 체계화된 장애 이력
관리를 통한 취약점 보완 가능

비용절감
고가용 구성을 위해 투입되는
HW, SW 라이선스, 유지보수
비용이 획기적으로 절감되며
자체 구축 대비 연간
약 60% 이상 비용 절감

업무 생산성 향상
Down Time 최소화에 따른
업무 효율 및 생산성 증대와
장애 처리에 따른
관리자 실수 최소화
효율적 운영
전문화된 운영 인력에 의한
위탁 운영과 자체 운영 인력 교육
등에 대한 비용 절감
상세 기능
주요 특징
-
통합 가용성 관제
- 웹 기반의 글로벌 관리 센터를 통해 여러 분산된 클러스터를 한 눈으로 관리할 수 있습니다.
- 운영체제, 응용프로그램, 서버, 스토리지, 지리적 위치 등에 구애받지 않고 단일 콘솔로 전체 인프라의 가용성을 지능적이면서도 매우 효율적으로 관리할 수 있습니다.
-
자동 HA/DR 프로비저닝
- 일반적으로 고가용성 및 재해복구를 구축하기 위해서는 복구 서버 준비, OS 및 애플리케이션 설치, HA/DR 소프트웨어 설치, 다양한 경우의 수를 대비한 복구 시나리오 스크립트 설정 등 수일에서 수주가 소요됩니다.
- MCCS는 자동화된 워크플로우 및 관리를 통해 수십 분 내 클러스터 및 재해복구를 구축할 수 있습니다.
-
사전 예방 모니터링
- 장애가 발생하기 전 이를 야기시킬 수 있는 사전 증상들, 즉 I/O 병목 현상, 비정상적인 자원 사용 등의 이벤트들이 있습니다.
- MCCS의 사전 예방 모니터링을 통해 장애로 이어지는 이벤트들을 사전에 예방할 수 있습니다.
- RDBMS와 같은 Tier 1 애플리케이션에 대한 확장 모니터링을 통해 장애로 이어지는 연결고리를 사전에 최소화할 수 있습니다.
-
가용성 현황 차트와 보고서
- 관리자들은 가용성 상태, 중요한 서비스의 현황 및 보고서를 주기적으로 요청하지만, 이에 대한 보고서를 만드는 작업 쉽지 않습니다.
- MCCS의 강력한 가용성 통계 기능을 통해 지정된 기간의 자원, 노드, 클러스터 그룹의 가용성 상태, 현황 등의 차트를 쉽게 출력할 수 있습니다.
서비스 플랜
| 항목 | 기능 | MCCS Workgroup | MCCS Enterprise |
|---|---|---|---|
| 구성 형태 | 물리 - 물리 | O | O |
| 물리 – 가상(VM) | O | O | |
| 가상 - 가상 | O | O | |
| Active – Standby | O | O | |
| Active – Active (상호대기) | O | O | |
| 외장 스토리지 공유 구성 | O | O | |
| 실시간 Block Level 복제 (Sync, Async) | O | O | |
| HA(local) – Remote 복제 | O | O | |
| 장애 감지 Filover | 시스템 장애감지 | O | O |
| DISK I/O 장애 감지 | O | O | |
| Applications 장애 감지 | O | O | |
| 네트워크 장애 감지 | O | O | |
| 모니터링 | WEB GUI(한글, 영문) | O | |
| 관제서버에서 통합관리 | O | ||
| 사전 감지 및 후속조치 | 자원감지(CPU, MEM, DISK) | O | |
| System, App 비정상 Trigger 조치 | O | ||
| Hung 조치 | SYSTEM 및 OS 행 조치 | O | |
| 알림 서비스 | SMS, e-mail, hangout | O | |
| 장애통계 및 리포트 | O |
주요 기능
-
서버 클러스터링
- MCCS는 서버 하드웨어, 소프트웨어, 네트워크, 스토리지 등 장애 유형에 관계없이 모든 애플리케이션을 24 x 7 x 365일 운영할 수 있습니다.
- 모든 애플리케이션의 유형에 대해서 보호가 가능하며, 서버 클러스터링을 통해 다운타임을 수분에서 수초로 최소화합니다.
- 하드웨어 및 스토리지 종류에 크게 구애받지 않고 다양한 환경에서의 구성을 지원합니다.
-
외장 공유 방식
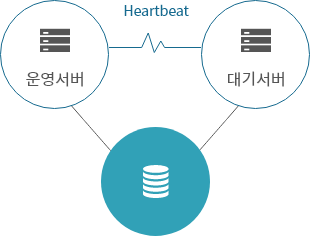
- 운영 / 대기 서버 간, 외장 디스크 공유
- 서버, 네트워크, 응용 프로그램, storage 패스 등의 장애 감시
- SAN, NAS, DAS, iSCSI 등 지원
-
서버 간 복제 방식
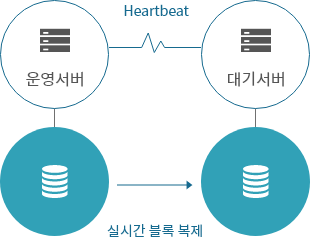
- 대상 서버 간, 네트워크 연결을 통한 스토리지 / 디스크 등 실시간 복제
- 가장 저렴하고 심플한 구성
- 성능 저하 거의 없이 복제 가능
-
원격지 재해 복구 방식
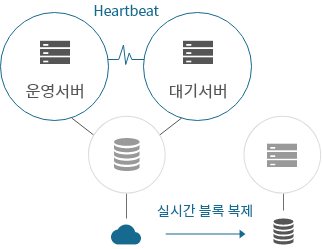
- 실시간 블록 복제를 원격지로 연장
- Single / HA 구성 서버 set → 원격지 구성
- 원격지에서의 복구에 대한 자동화된 워크플로우 지원
-
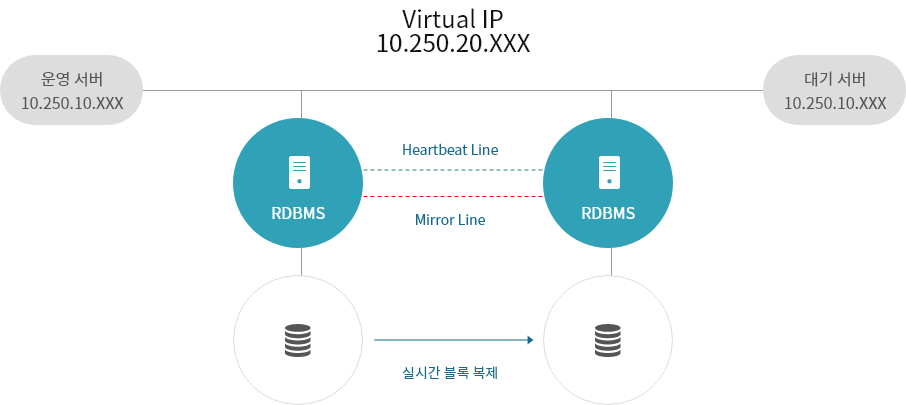
실시간 블록 복제
- 블록 레벨 복제로 타깃과 소스의 데이터 정합성을 보장합니다.
- 두 서버 사이에 데이터 복제 모듈이 구성되면, 소스 볼륨에 쓰기 작업 발생 시 TCP/IP 네트워크를 통해 타깃 볼륨에 동시에 쓰기 작업을 수행합니다.
- MCCS는 모든 종류의 파일과 데이터베이스를 지원하며, 장애 및 재해에 대해서 중요한 데이터가 손실되지 않습니다.
-
통합 가용성 관리
- 웹 기반의 글로벌 관리 센터를 통해 분산된 클러스터를 한 눈으로 관리할 수 있습니다.
- 단일 콘솔로 전체 인프라의 가용성을 직관적이고, 효율적으로 관리할 수 있습니다.